What is a supervised learning ?
Supervised learning is a fundamental concept in machine learning, where an algorithm learns from labeled data to make predictions or decisions. In supervised learning, the algorithm is trained on a dataset consisting of input-output pairs, where the inputs (features) are associated with corresponding outputs (labels or target variables).
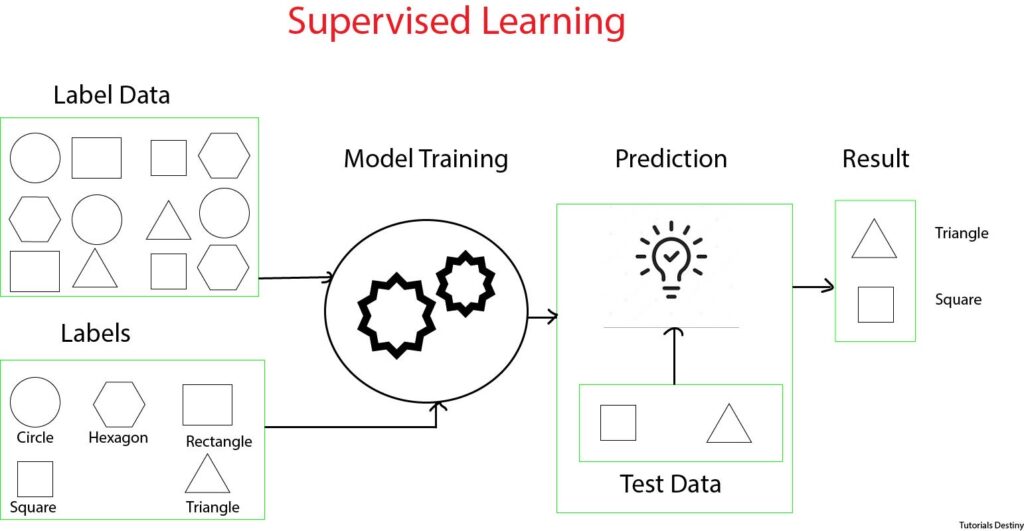
Here’s how supervised learning works:
- Training Phase: During the training phase, the algorithm learns from the labeled dataset to create a model that can map inputs to outputs. The labeled dataset is divided into two parts: the training set and the validation set. The training set is used to train the model, while the validation set is used to evaluate the model’s performance and adjust hyperparameters.
- Model Representation: The model learns a mapping function that approximates the relationship between the input features and the target variable. This mapping function can take various forms, depending on the specific algorithm used for supervised learning. For example, in linear regression, the mapping function is a linear equation, while in decision trees, it is a tree-like structure of decision rules.
- Prediction Phase: Once the model is trained, it can be used to make predictions on new, unseen data. The model takes input features as input and generates predictions or decisions as output. The performance of the model is evaluated using metrics such as accuracy, precision, recall, or F1-score, depending on the nature of the problem (classification or regression) and the specific requirements.
Supervised learning can be further categorized into two main types:
- Classification: In classification tasks, the target variable is categorical, meaning it belongs to a discrete set of classes or categories. The goal is to predict the class label of new instances based on their input features. Common algorithms for classification include logistic regression, decision trees, random forests, support vector machines (SVM), and neural networks.
- Regression: In regression tasks, the target variable is continuous, meaning it can take any real-numbered value within a range. The goal is to predict a numerical value or quantity based on the input features. Linear regression, polynomial regression, decision trees, random forests, and neural networks are commonly used for regression tasks.
Supervised learning is widely used in various applications, including but not limited to:
- Predictive analytics
- Image classification
- Speech recognition
- Natural language processing
- Recommender systems
- Financial forecasting
Overall, supervised learning plays a crucial role in solving real-world problems by enabling machines to learn from labeled data and make intelligent decisions or predictions.