Unsupervised learning is a machine learning paradigm where the algorithm learns from unlabeled data to discover patterns, structures, or relationships within the data. Unlike supervised learning, unsupervised learning does not require labeled output data. Instead, the algorithm seeks to find inherent structures or hidden patterns within the input data.
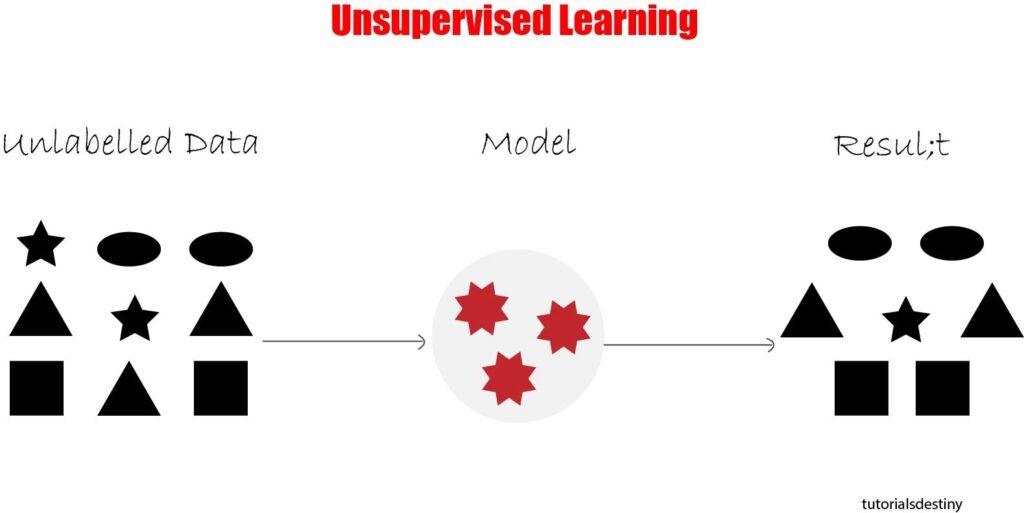
Here’s how unsupervised learning works:
- Training Phase: During the training phase, the algorithm is presented with a dataset consisting only of input features, without any corresponding output labels. This dataset is often referred to as an “unlabeled dataset.” The algorithm’s objective is to explore and identify meaningful patterns or structures within the data without explicit guidance or supervision.
- Pattern Discovery: Unsupervised learning algorithms aim to uncover inherent structures or relationships within the data, such as clusters, associations, or anomalies. The algorithm may identify clusters of similar data points, discover associations between different features, or detect outliers or anomalies that deviate significantly from the norm.
- Model Representation: The output of an unsupervised learning algorithm typically consists of learned representations or transformations of the input data. These representations capture the underlying structure or patterns within the data and can be used for various purposes, such as data visualization, dimensionality reduction, or feature engineering.
- Evaluation: Unlike supervised learning, where performance can be evaluated using metrics such as accuracy or precision, evaluating the performance of unsupervised learning algorithms can be more challenging. Evaluation metrics depend on the specific task and objectives of the algorithm. For example, clustering algorithms may be evaluated based on clustering quality measures such as silhouette score or Davies-Bouldin index.
Unsupervised learning can be further categorized into several main types:
- Clustering: Clustering algorithms group similar data points together into clusters based on their intrinsic similarities. Examples of clustering algorithms include k-means clustering, hierarchical clustering, and DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
- Dimensionality Reduction: Dimensionality reduction techniques aim to reduce the number of features or dimensions in the dataset while preserving as much relevant information as possible. Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and Autoencoders are commonly used for dimensionality reduction.
- Association Rule Learning: Association rule learning algorithms identify relationships or associations between different features or items in a dataset. These algorithms are commonly used in market basket analysis and recommendation systems to discover patterns in transactional data. Apriori and FP-Growth are examples of association rule learning algorithms.
Unsupervised learning has numerous applications across various domains, including but not limited to:
- Anomaly detection
- Customer segmentation
- Image and text clustering
- Data preprocessing and feature engineering
- Recommender systems
- Generative modeling and data synthesis
Overall, unsupervised learning plays a vital role in exploratory data analysis, pattern discovery, and knowledge discovery from unlabeled data, providing valuable insights and facilitating decision-making in diverse fields.