Introduction
Overfitting and underfitting are critical challenges in machine learning. Both issues impact model performance and generalization, making it essential to identify and address them effectively. In this article, we’ll cover:
- Definitions of overfitting and underfitting.
- Symptoms and detection techniques.
- Solutions and techniques for mitigation.
What Are Overfitting and Underfitting?
Overfitting:
When a model learns the noise or details of the training data too well, it performs exceptionally on the training set but poorly on unseen data. Overfitting models fail to generalize.
- Example: A decision tree that grows too deep and memorises every detail of the training data, including outliers.
Illustration:- Training Accuracy: 99%
- Validation Accuracy: 70%
Underfitting:
When a model is too simple to capture the underlying patterns of the data, it performs poorly on both training and unseen data.
- Example: A linear regression model used for a dataset with nonlinear relationships.
Illustration:- Training Accuracy: 65%
- Validation Accuracy: 60%
Symptoms and Detection
| Symptom | Overfitting | Underfitting |
|---|---|---|
| Training Accuracy | High | Low |
| Validation Accuracy | Low | Low |
| Performance Gap | Significant difference between train/val. | Similar poor performance on both datasets |
| Learning Curve | High train accuracy, plateaued val accuracy | Both train and val accuracies are low |
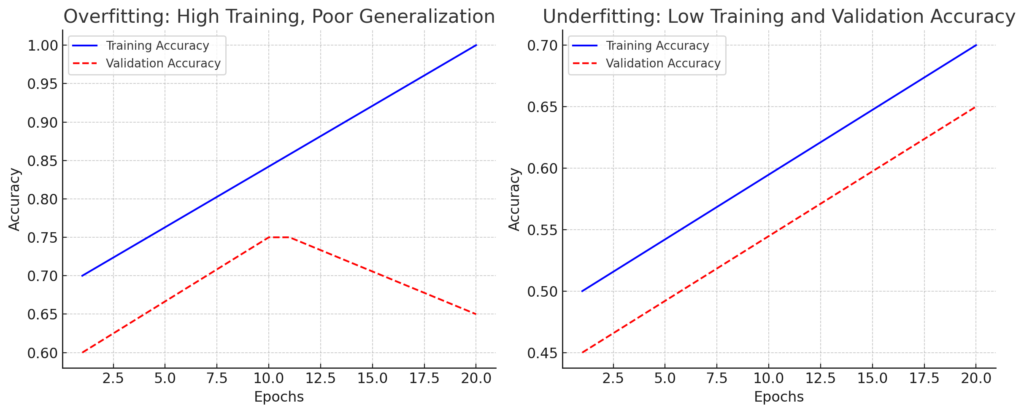
Here’s the learning curve visualization for overfitting and underfitting!
- Left Plot (Overfitting): Training accuracy remains high, but validation accuracy peaks and drops.
- Right Plot (Underfitting): Both training and validation accuracies stay low, indicating an underpowered model.
Techniques to Address Overfitting
- Regularization:
- L1 Regularization: Adds absolute value of coefficients as a penalty term (sparse solutions).
- L2 Regularization: Adds squared value of coefficients as a penalty term (reduces magnitude).
- Elastic Net: Combines L1 and L2 regularization for better flexibility.
- Example in Scikit-learn:
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0) # L2 regularization
model.fit(X_train, y_train)
- Dropout (for Neural Networks):
- Randomly deactivate neurons during training to prevent reliance on specific features.
- Example in TensorFlow:
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.5)) # 50% dropout rate
- Data Augmentation:
- Increase dataset size artificially by applying transformations like rotation, flipping, or scaling for image datasets.
- Example:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rotation_range=30, horizontal_flip=True)
- Simplify the Model:
- Reduce complexity by limiting the number of layers, parameters, or depth of trees.
- Early Stopping:
- Stop training when validation performance stops improving.
- Example in TensorFlow:
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
Techniques to Address Underfitting
- Increase Model Complexity:
- Add more layers or parameters to neural networks.
- Use a more complex algorithm (e.g., Random Forest instead of Logistic Regression).
- Feature Engineering:
- Create meaningful features using transformations, polynomial expansions, or feature selection.
- Example: Polynomial features in Scikit-learn:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
- Hyperparameter Tuning:
- Optimize parameters like learning rate, tree depth, or kernel functions.
- Use libraries like GridSearchCV, RandomizedSearchCV, or Optuna.
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(estimator=model, param_grid=params, cv=5)
grid.fit(X_train, y_train)
- Increase Training Time:
- Allow the model to learn more by training for additional epochs or iterations.
- Improve Feature Representation:
- Use embeddings for categorical variables or advanced techniques like autoencoders for dimensionality reduction.
Case Study: Fixing Overfitting and Underfitting in House Price Prediction
Real-World Example: Addressing Overfitting and Underfitting
Scenario: You’re building a model to predict house prices.
Issue 1: Overfitting
- Model: Deep Neural Network with 10 hidden layers.
- Symptom: Validation loss increases while training loss decreases.
Solution:
- Add L2 regularization and dropout layers.
- Use early stopping.
- Apply data augmentation to artificially increase dataset size.
Issue 2: Underfitting
- Model: Linear Regression.
- Symptom: Both training and validation errors are high.
Solution:
- Switch to a nonlinear model like Gradient Boosting.
- Engineer features, such as interaction terms (e.g., “square footage × number of bedrooms”).
- Tune hyperparameters for optimal performance.
Practical Tips
- Understand Your Data: Ensure sufficient and high-quality data. Poor data quality often causes underfitting.
- Monitor Learning Curves: Always plot training and validation accuracy/loss over epochs to detect overfitting or underfitting early.
- Balance Simplicity and Complexity: Avoid overly complex models for small datasets, and ensure sufficient complexity for capturing intricate patterns.
This comprehensive guide ensures that you can tackle overfitting and underfitting challenges effectively, improving the performance and reliability of your machine learning models.
➡️ Next Topic: Benchmarking and Finalizing Models