Introduction
The k-Nearest Neighbors (k-NN) algorithm is one of the simplest and most intuitive machine learning algorithms. Despite its simplicity, it has proven to be extremely powerful in solving classification and regression problems across many fields such as image recognition, recommendation systems, and medical diagnosis.
However, classical k-NN suffers from a major limitation: computational inefficiency when dealing with large datasets or high-dimensional data. The algorithm requires calculating the distance between a query point and every point in the training dataset. As the dataset grows, this process becomes slower and increasingly expensive.
This limitation has motivated researchers to explore quantum computing techniques that can accelerate such operations. One promising approach is Quantum k-Nearest Neighbors (Quantum k-NN), a quantum-enhanced version of the classical k-NN algorithm.
Quantum k-NN uses principles of quantum mechanics, including superposition, entanglement, and quantum parallelism, to represent data and compute distances between data points more efficiently. Instead of comparing a test sample with each training example sequentially, a quantum computer can process many comparisons simultaneously.
In theory, this capability can dramatically reduce computational complexity, making quantum k-NN a promising algorithm for large-scale machine learning tasks.
In this section, we will explore:
- The basics of classical k-NN
- The limitations of classical approaches
- The concept and workflow of quantum k-NN
- Quantum data encoding techniques
- Quantum distance computation methods
- Implementation approaches using quantum frameworks
- Real-world applications
- Advantages and challenges of the algorithm
Classical k-Nearest Neighbors: A Quick Review
Before understanding the quantum version, it is important to recall how the classical k-Nearest Neighbors algorithm works.
The main idea behind k-NN is simple:
Data points with similar characteristics tend to belong to the same class.
Instead of learning a complex mathematical model, k-NN simply stores all training data and makes predictions by comparing new samples with existing ones.
Because of this property, it is known as a lazy learning algorithm.
Key Characteristics of Classical k-NN
1. No Training Phase
Unlike algorithms such as neural networks or decision trees, k-NN does not build a model during training.
Instead:
- The training dataset is stored directly.
- All computation occurs during prediction.
This makes the algorithm simple but computationally expensive during inference.
2. Distance-Based Learning
To classify a new data point, the algorithm calculates the distance between the query point and every point in the training dataset.
Common distance metrics include:
Euclidean Distance
Manhattan Distance
\[d(x,y) = \sum_{i=1}^{n}|x_i-y_i|\]
Cosine Similarity
Used especially in text or high-dimensional datasets.
3. Neighbor Selection
Once distances are calculated:
- The k nearest neighbors are selected.
- These are the training samples with the smallest distance from the query point.
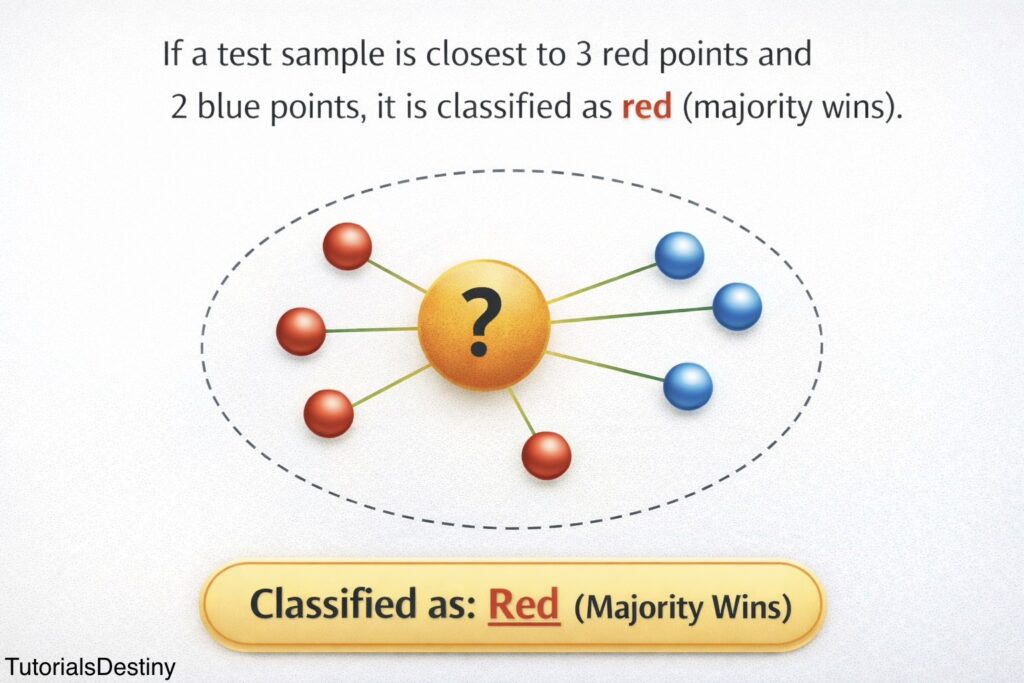
4. Majority Voting
For classification tasks:
- The algorithm counts the labels among the k nearest neighbors.
- The most common label becomes the predicted class.
Example:
| Neighbor | Label |
| 1 | Red |
| 2 | Blue |
| 3 | Red |
| 4 | Red |
| 5 | Blue |
Majority = Red
Prediction = Red
Limitations of Classical k-NN
Although k-NN is conceptually simple, it faces several practical challenges.
1. High Computational Cost
For every prediction:
- Distance must be computed against all training samples.
If there are:
- n training samples
- d features
The complexity becomes:
\[O(n × d)\]
This becomes expensive for large datasets.
2. Curse of Dimensionality
As the number of features increases:
- Distances between points become less meaningful.
- Data becomes sparse.
This phenomenon is known as the curse of dimensionality.
3. Memory Requirements
k-NN must store the entire training dataset, which can become large.
4. Slow Inference
Prediction time grows with dataset size.
For large-scale applications like:
- Image recognition
- Genomics
- Financial datasets
This becomes a bottleneck.
Enter Quantum k-Nearest Neighbors
Quantum k-NN attempts to overcome these limitations by using quantum computing principles.
Instead of storing data classically and computing distances sequentially, quantum algorithms represent data as quantum states.
These states exist in superposition, allowing multiple computations to occur simultaneously.
Key idea:
Use quantum circuits to compute similarities between data points faster than classical algorithms.
Quantum k-NN replaces classical distance computation with quantum state overlap measurement, which can be estimated efficiently on quantum hardware.
Core Enhancements in Quantum k-NN
Quantum k-NN differs from classical k-NN in several important ways.
1. Quantum Data Representation
Classical data vectors are converted into quantum states.
For example:
\[x_i \rightarrow |\psi(x_i)\rangle\]
This allows the data to be processed by quantum circuits.
2. Parallel Similarity Evaluation
Because of quantum superposition, the system can evaluate similarities between the test sample and many training samples simultaneously.
This creates the potential for major computational speedups.
3. Quantum Distance Metrics
Instead of classical distance formulas, quantum k-NN uses:
- Fidelity
- Inner product estimation
- Swap test circuits
These methods estimate the similarity between two quantum states.
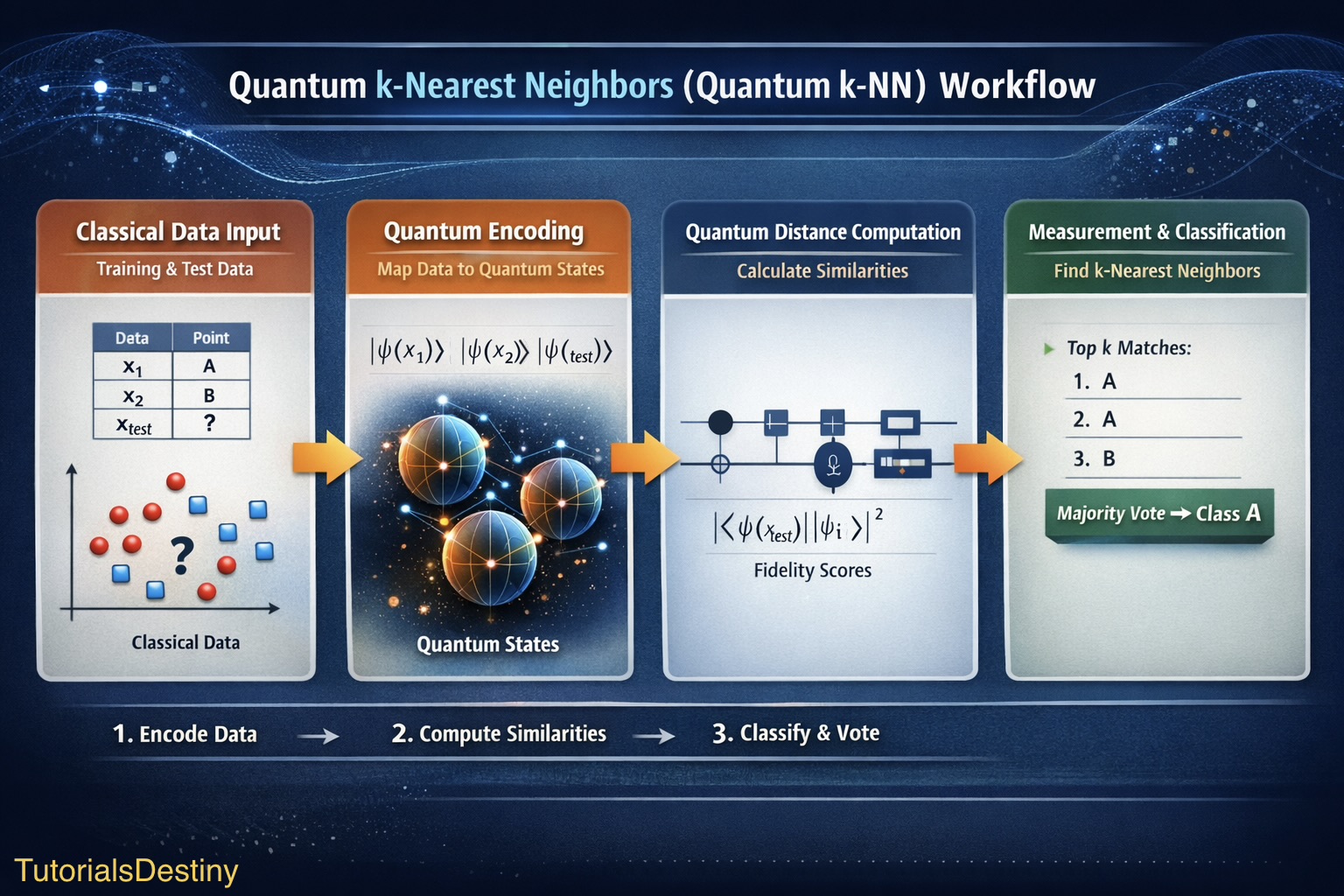
Workflow of Quantum k-NN
The algorithm typically follows several stages.
Step 1: Input Classical Data
The dataset consists of:
- Training vectors
- Corresponding labels
- A query vector to classify
Example:
| Data Point | Features | Label |
| x₁ | (2,3) | A |
| x₂ | (5,7) | B |
| x₃ | (1,2) | A |
Step 2: Quantum Data Encoding
Classical data must be converted into quantum form.
This is called quantum state preparation.
Each vector is mapped to a quantum state:
\[x_i \rightarrow |\psi(x_i)\rangle\]
Quantum Data Encoding Techniques
Several encoding strategies exist.
1. Amplitude Encoding
Data values are stored in the amplitudes of a quantum state.
Example:
A vector
\[(0.5,0.5,0.5,0.5)\]
can be encoded into:
\[|\psi\rangle = 0.5|00\rangle + 0.5|01\rangle + 0.5|10\rangle + 0.5|11\rangle\]
Advantages:
- Exponentially efficient storage
- Only \(log₂(N)\) qubits required
Challenge:
- State preparation can be complex.
2. Angle Encoding
Data values are encoded as rotation angles of qubits.
Example:
\[R_y(x_i)\]
rotations represent feature values.
Advantages:
- Easier to implement
- Works well on NISQ hardware.
3. Basis Encoding
Data values are encoded directly into qubit states:
Example:
| Classical | Quantum |
| 0 | |0⟩ |
| 1 | |1⟩ |
Used for discrete datasets.
Step 3: Quantum Distance Calculation
Once data is encoded, we must measure similarity between states.
One popular method is the Swap Test.
The swap test estimates the overlap between two quantum states.
If two states are identical:
Probability of measurement = 1
If they are very different:
Probability approaches 0
Mathematically, the similarity between two states is:
\[|\langle \psi(x_{train}) | \psi(x_{test}) \rangle|^2\]
This quantity represents fidelity.
Swap Test Circuit
The swap test works as follows:
- Prepare two quantum states.
- Add an ancilla qubit.
- Apply a Hadamard gate.
- Perform a controlled swap.
- Apply another Hadamard gate.
- Measure the ancilla.
The probability of measuring 0 reveals the similarity between the states.
This approach allows similarity estimation without measuring the data qubits directly.
Step 4: Parallel Distance Evaluation
Using quantum superposition, the system can evaluate similarities with multiple training states simultaneously.
This is where quantum computing offers a theoretical advantage.
Instead of sequential distance calculations:
distance(test, x1)
distance(test, x2)
distance(test, x3)quantum circuits evaluate them in parallel.
Step 5: Measurement and Decision
After running the quantum circuit:
- Measurement outcomes encode similarity information.
- The k most similar training states are selected.
- Their labels are collected.
- Majority voting determines the prediction.
Pseudocode Representation
Below is a conceptual pseudocode representation of the algorithm.
Input:
Training dataset (X, Y)
Test sample x_test
Number of neighbors k
Step 1: Encode classical data into quantum states
for each training_vector in X:
prepare quantum state |ψ(training_vector)>
prepare quantum state |ψ(x_test)>
Step 2: Estimate similarity
for each training_state:
fidelity = overlap(|ψ(training_vector)>, |ψ(x_test)>)
store (fidelity, label)
Step 3: Select k highest fidelities
Step 4: Majority vote among k labels
Output: predicted labelActual implementations require quantum programming frameworks such as:
- Qiskit
- PennyLane
- Cirq
Implementation Example (Conceptual)
A simplified implementation using Qiskit might involve:
- Creating quantum registers
- Encoding feature vectors
- Running swap test circuits
- Measuring similarity scores
Hybrid quantum-classical systems are often used, where:
- Quantum computers compute similarities.
- Classical computers perform final classification.
Applications of Quantum k-NN
Quantum k-NN could transform many domains where distance-based learning is important.
1. Medical Diagnosis
Patient symptoms or medical imaging data can be compared with previous cases to classify diseases.
Quantum k-NN may enable faster analysis of large medical datasets.
2. Image Recognition
In computer vision tasks, images are often represented as high-dimensional feature vectors.
Quantum algorithms could process such data more efficiently.
3. Financial Data Analysis
Large financial datasets involve:
- Market signals
- Economic indicators
- Transaction patterns
Quantum similarity search may accelerate pattern recognition.
4. Quantum Chemistry
Quantum systems can naturally represent molecular states.
Quantum k-NN may help classify:
- Molecular structures
- Chemical reactions
- Material properties
5. Pattern Recognition
Applications include:
- Speech recognition
- Signal processing
- Fraud detection
Strengths of Quantum k-NN
Quantum k-NN offers several theoretical advantages.
1. Potential Speedup
Quantum algorithms may reduce computational complexity.
Some implementations suggest quadratic speedups in similarity search.
2. Natural Handling of High-Dimensional Data
Quantum states can represent very large vectors efficiently.
For example:
n qubits represent 2ⁿ states simultaneously.
3. Parallel Similarity Estimation
Quantum circuits can evaluate multiple distances simultaneously.
4. Compatibility with Hybrid Systems
Quantum k-NN can be integrated into hybrid architectures where:
- Quantum processors compute similarity.
- Classical systems perform decision making.
Challenges and Limitations
Despite its promise, quantum k-NN faces significant obstacles.
1. Data Encoding Overhead
Preparing quantum states from classical data can be expensive.
In many cases, encoding may cancel out the theoretical speed advantage.
2. Limited Quantum Hardware
Current quantum devices are NISQ machines (Noisy Intermediate-Scale Quantum).
They have:
- Limited qubits
- High error rates
- Short coherence times
3. Noise Sensitivity
Quantum circuits are sensitive to noise and measurement errors.
Accurate similarity estimation requires stable hardware.
4. Scalability
Large datasets require:
- More qubits
- Deeper circuits
This remains a challenge for current hardware.
Theoretical Runtime Advantage
Some quantum nearest neighbor algorithms achieve complexity:
\[O(\sqrt{N})\]
compared to classical complexity:
\[O(N)\]
This square-root speedup can be significant for very large datasets.
However, the practical benefit depends on efficient quantum data loading.
Future of Quantum k-NN
As quantum hardware improves, quantum machine learning algorithms such as quantum k-NN may become practical.
Research directions include:
- Efficient quantum data encoding
- Noise-resistant quantum circuits
- Hybrid quantum-classical architectures
- Quantum kernel methods
These developments may enable powerful quantum-accelerated machine learning systems.
Summary
Quantum k-Nearest Neighbors is a promising quantum machine learning algorithm that enhances the classical k-NN approach using quantum principles.
Key ideas include:
- Encoding classical data into quantum states
- Using quantum circuits to estimate similarity
- Exploiting quantum parallelism for faster computation
Although practical implementation is currently limited by hardware constraints, ongoing research suggests that quantum k-NN could become an important tool for solving large-scale machine learning problems.
🔗 What’s Next?
➡️ Next: Quantum Support Vector Machines (Quantum SVMs)
In the next section, we’ll see how quantum kernels power Support Vector Machines, another powerful ML model, and how quantum features can boost classification performance.