From Biological Inspiration to Intelligent Machines
Artificial Intelligence has undergone several transformative phases throughout its history. Early AI systems relied heavily on manually programmed rules, where developers explicitly instructed computers how to respond to specific situations. While effective for simple tasks, these systems struggled when faced with complex real-world problems involving uncertainty, ambiguity, or massive amounts of data.
The emergence of Machine Learning changed this paradigm by enabling computers to learn patterns from data rather than relying entirely on human-written rules. However, even traditional Machine Learning approaches have limitations when dealing with highly complex tasks such as image recognition, speech understanding, natural language processing, and autonomous decision-making.
To overcome these challenges, researchers turned to one of nature’s most sophisticated learning systems: the human brain.
This inspiration led to the development of Artificial Neural Networks, computational models designed to mimic certain aspects of biological learning. Although artificial neural networks are vastly simpler than the human brain, they have proven remarkably effective at learning patterns, recognizing relationships, and solving problems that once seemed impossible for machines.
Today, neural networks power many of the technologies we use every day, including voice assistants, recommendation systems, autonomous vehicles, medical imaging tools, language translation systems, and generative AI models such as ChatGPT.
In this lesson, we will explore how biological inspiration led to artificial neural networks, understand the fundamental components of these systems, and examine why neural networks became the foundation of modern Artificial Intelligence.
The Rise of Neural Networks
The journey toward neural networks was not straightforward. For decades, researchers sought methods that could help machines learn and adapt.
Early AI systems performed well in structured environments but struggled when faced with tasks requiring perception, pattern recognition, or decision-making in uncertain situations.
Consider image recognition.
A traditional rule-based system would require developers to explicitly define every possible variation of an object:
- Different sizes
- Different angles
- Different lighting conditions
- Different backgrounds
This quickly becomes impossible. Humans, however, can instantly recognize a cat whether it appears in bright sunlight, dim lighting, or partially hidden behind another object.
Researchers began asking an important question:
How does the human brain perform such complex recognition tasks so efficiently?
The search for answers eventually led to the development of neural network models inspired by biological neurons.
Why Traditional Machine Learning Has Limits
Before understanding neural networks, it is important to recognize the challenges they were designed to solve.
Traditional Machine Learning algorithms such as:
- Linear Regression
- Logistic Regression
- Decision Trees
- Support Vector Machines
can perform exceptionally well on structured datasets.
For example:
- Predicting house prices
- Customer churn prediction
- Sales forecasting
- Fraud detection
However, many real-world problems involve highly complex and unstructured data.
Examples includes images, videos, audio recordings, human language and sensor streams
In these situations, manually designing useful features becomes extremely difficult. Imagine building a system that identifies dogs in photographs.
A developer would need to define:
- Ear shapes
- Fur textures
- Body structures
- Color variations
- Viewing angles
The complexity quickly becomes overwhelming. Neural networks solve this challenge by learning features automatically from data.
Instead of manually specifying what to look for, the system learns relevant patterns through experience.
This ability transformed the field of Artificial Intelligence.
The Human Brain: Nature’s Learning Machine
The human brain remains one of the most extraordinary information-processing systems known.
Despite consuming relatively little energy, it can:
- Recognize faces instantly
- Understand spoken language
- Learn new skills
- Solve complex problems
- Adapt to changing environments
The brain accomplishes these tasks through billions of interconnected neurons.
Each neuron processes information and communicates with other neurons through electrical and chemical signals.
Although artificial neural networks are vastly simpler than biological brains, they borrow several key concepts from this natural architecture.
Understanding biological neurons helps us understand why neural networks were designed the way they are.
How Biological Neurons Work
A biological neuron consists of several important components.
Dendrites
Dendrites receive incoming signals from other neurons.
They function as information collectors.
Thousands of signals may arrive simultaneously from neighboring neurons.
Cell Body
The cell body processes incoming information.
It integrates signals received through the dendrites and determines whether the neuron should activate.
Axon
The axon carries signals away from the neuron.
Once activated, the neuron transmits information through its axon to other neurons.
Synapses
Synapses are communication junctions between neurons.
They control how strongly information is transmitted from one neuron to another.
Learning occurs partly through changes in synaptic strength.
The stronger a connection becomes, the more influence one neuron has on another.
Learning in the Human Brain
Imagine learning to ride a bicycle. Initially, balancing feels difficult. After repeated practice, neural connections strengthen.
Tasks that once required significant effort eventually become automatic. The brain adapts by adjusting the strength of connections between neurons.
This concept inspired the idea of weighted connections in artificial neural networks.
While artificial systems are far simpler, they use a similar principle. Learning involves adjusting connection strengths to improve performance.
From Biological Neurons to Artificial Neurons
Researchers sought to create computational models that captured the essential behavior of biological neurons.
The goal was not to perfectly replicate the brain. Instead, they wanted to reproduce key learning mechanisms.
An artificial neuron receives inputs, processes them, and produces an output. This process resembles how biological neurons receive, process, and transmit information.
A simplified artificial neuron consists of:
- Inputs
- Weights
- Summation
- Activation Function
- Output
These components form the foundation of every neural network.
The Birth of Artificial Neural Networks
The concept of artificial neurons dates back to the 1940s. Researchers sought mathematical models capable of simulating learning behavior.
One of the earliest and most influential models was developed by Warren McCulloch and Walter Pitts
Their work demonstrated how networks of simple computational units could perform logical operations. This groundbreaking research laid the foundation for modern neural networks.
Although primitive by today’s standards, these early models introduced many concepts still used in deep learning systems.
Understanding the Perceptron
The perceptron was one of the earliest practical neural network models. It represented a significant milestone in the development of Artificial Intelligence.
A perceptron receives multiple inputs and combines them to produce a decision.
For example:
A bank might evaluate:
- Income
- Credit score
- Existing debt
to determine whether a loan should be approved.
Similarly, a perceptron evaluates multiple inputs and generates an output based on learned relationships.
The perceptron introduced the idea that machines could learn decision boundaries from data rather than relying entirely on manually defined rules.
Components of a Perceptron
A perceptron consists of four primary elements:
Inputs: It represent information entering the neuron.
Examples:
- Age
- Income
- House size
- Temperature
Each input provides information relevant to the prediction task.
Weights: Not all inputs are equally important. Weights determine the importance of each input.
For example:
When predicting house prices:
- Location may be highly important.
- Wall color may have little impact.
Weights allow the model to emphasize relevant information.
Summation: The neuron multiplies each input by its corresponding weight and then adds the results. This creates a weighted sum.
The weighted sum represents the neuron’s combined assessment of all available information.
Output: The neuron uses the weighted information to generate a prediction or decision. This output becomes the basis for further processing or final classification.
Inputs, Weights, and Learning
Weights are among the most important concepts in neural networks.
Consider the following example.
A university wants to predict whether a student will pass an examination.
Inputs might include:
- Attendance
- Assignment scores
- Practice tests
Initially, the model does not know which factors matter most. Through training, it gradually learns appropriate weights.
For example:
Attendance → High Weight
Assignments → Medium Weight
Practice Tests → High Weight
Learning essentially means finding the best weights. As training progresses, weights are adjusted repeatedly to improve predictions.
How an Artificial Neuron Makes Decisions
Suppose a neuron receives the following inputs:
Study Hours
Attendance
Practice Tests
Each input has a corresponding weight.
The neuron:
- Multiplies inputs by weights.
- Calculates a weighted sum.
- Applies a decision mechanism.
- Produces an output.
This process allows the neuron to convert raw information into meaningful predictions. Although simple individually, large collections of neurons can solve remarkably complex problems.
The Need for Activation Functions
If neurons only performed weighted addition, neural networks would remain extremely limited. They would behave similarly to simple linear models.
Real-world problems are rarely linear.
Consider:
- Image recognition
- Speech understanding
- Language translation
These tasks involve highly complex relationships. Neural networks require a mechanism that introduces non-linearity.
This mechanism is called an activation function.
Activation functions enable networks to learn sophisticated patterns that simple mathematical equations cannot capture.
Why Activation Functions Matter
Activation functions determine whether a neuron should become active.
They help networks:
- Learn complex relationships
- Capture non-linear patterns
- Solve challenging AI tasks
- Build deep hierarchical representations
Without activation functions, modern deep learning would not exist.
Now, we know how biological neurons inspired artificial neural networks and learned how individual artificial neurons process information using inputs, weights, and outputs.
However, a single neuron alone has limited capabilities.
While it can make simple decisions, it cannot recognize faces, understand speech, translate languages, or generate human-like text.
The true power of neural networks emerges when many neurons work together in organized layers.
Before understanding how these layers cooperate, we must first examine one of the most important innovations in neural network design: activation functions.
Without activation functions, modern Deep Learning would not exist.
Why Neural Networks Need Activation Functions
Imagine a neural network designed to recognize handwritten digits.
The network receives pixel values from an image and processes them through multiple layers.
If each neuron simply performed weighted addition, every layer would behave like a basic mathematical equation.
Even if we stacked hundreds of layers together, the entire network would still behave like a simple linear model.
This creates a major limitation. Real-world problems are rarely linear.
Consider:
- Human language
- Speech recognition
- Medical diagnosis
- Facial recognition
- Autonomous driving
These tasks involve highly complex relationships that cannot be represented by simple straight-line equations.
Activation functions solve this problem by introducing non-linearity into neural networks. This allows networks to learn sophisticated patterns and relationships hidden within data.
Understanding Non-Linearity
Suppose you are predicting exam performance.
A student who studies twice as long does not necessarily score exactly twice as many marks.
Similarly:
- Increasing advertising budget does not always double sales.
- Increasing temperature does not always increase electricity consumption proportionally.
- Increasing training data does not always improve model performance at a fixed rate.
These are examples of non-linear relationships.
Modern AI systems succeed because they can learn such relationships automatically. Activation functions make this possible.
What Does an Activation Function Do?
After a neuron calculates its weighted sum, the result passes through an activation function.
The activation function determines:
- Whether the neuron should activate
- How strongly it should activate
- What information should move to the next layer
The output produced by the activation function becomes the neuron’s final output.
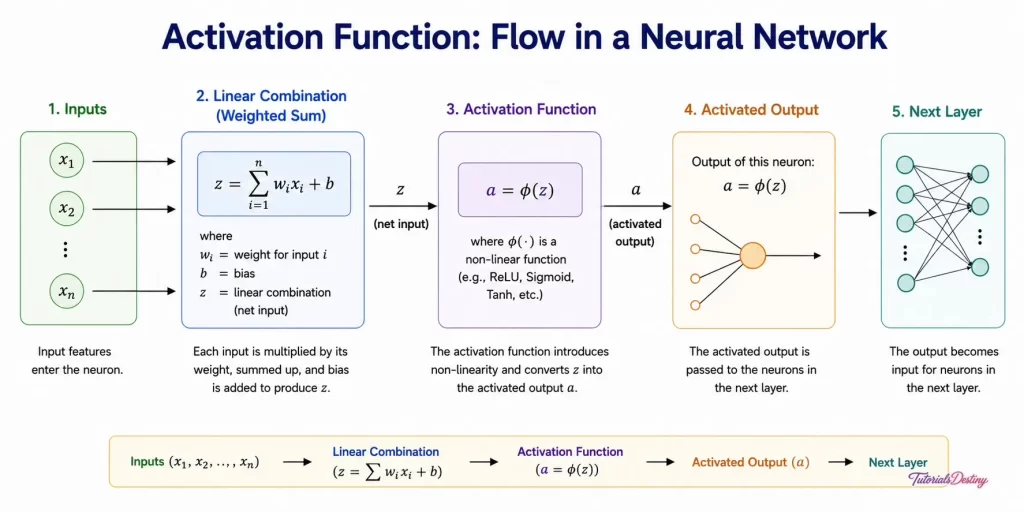
This process occurs millions or even billions of times inside modern AI systems.
The Step Function
One of the earliest activation functions was the Step Function. It works like a simple on-off switch.
If the weighted sum exceeds a threshold:
Output = 1
Otherwise:
Output = 0
This behavior resembles the original perceptron model.
How the Step Function Works
Imagine a loan approval system.
If an applicant’s score exceeds a certain threshold:
Approve Loan
Otherwise:
Reject Loan
The Step Function follows a similar principle.
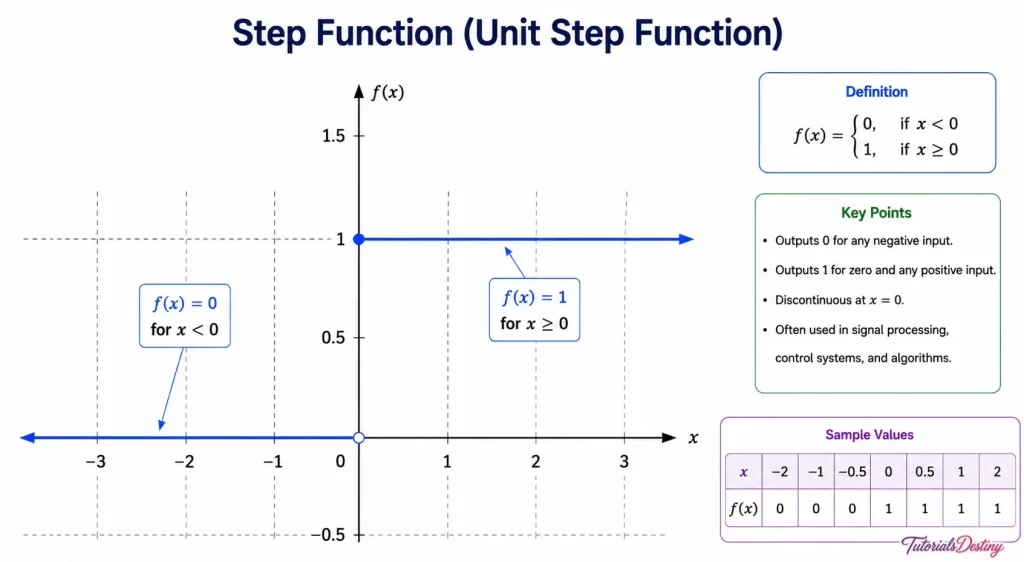
While simple, this function has serious limitations.
Why the Step Function Became Obsolete
The Step Function produces abrupt transitions. Small input changes near the threshold can cause dramatic output changes.
More importantly, it does not support gradient-based learning techniques that power modern deep learning.
As neural networks became more sophisticated, researchers needed smoother alternatives.
The Sigmoid Function
The Sigmoid Function became one of the most influential activation functions in neural network history.
Instead of producing only 0 or 1, it generates values between 0 and 1. This makes outputs more flexible and interpretable.
Visualizing the Sigmoid Function
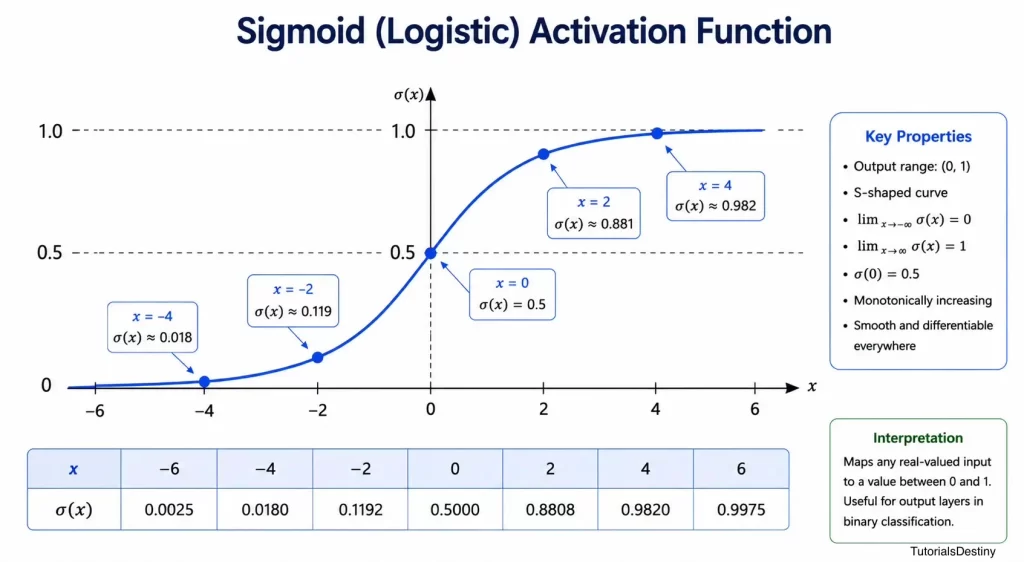
The characteristic S-shaped curve gives the function its name.
Why Sigmoid Was Popular
The Sigmoid Function offers several advantages:
- Smooth output transitions
- Probability-like outputs
- Differentiable behavior
- Useful for binary classification
For many years, it was widely used in neural networks.
Limitations of Sigmoid
Despite its success, Sigmoid has several weaknesses.
Vanishing Gradient Problem: As outputs approach 0 or 1, gradients become extremely small. This slows learning dramatically.
Computational Cost: Sigmoid requires more mathematical operations than newer activation functions.
Saturation: Large positive or negative inputs produce nearly constant outputs.
As a result, modern deep networks rarely use Sigmoid in hidden layers.
The Tanh Function
The Hyperbolic Tangent (Tanh) function improves upon several limitations of Sigmoid. Instead of producing outputs between 0 and 1, it produces outputs between -1 and +1
Tanh Visualization
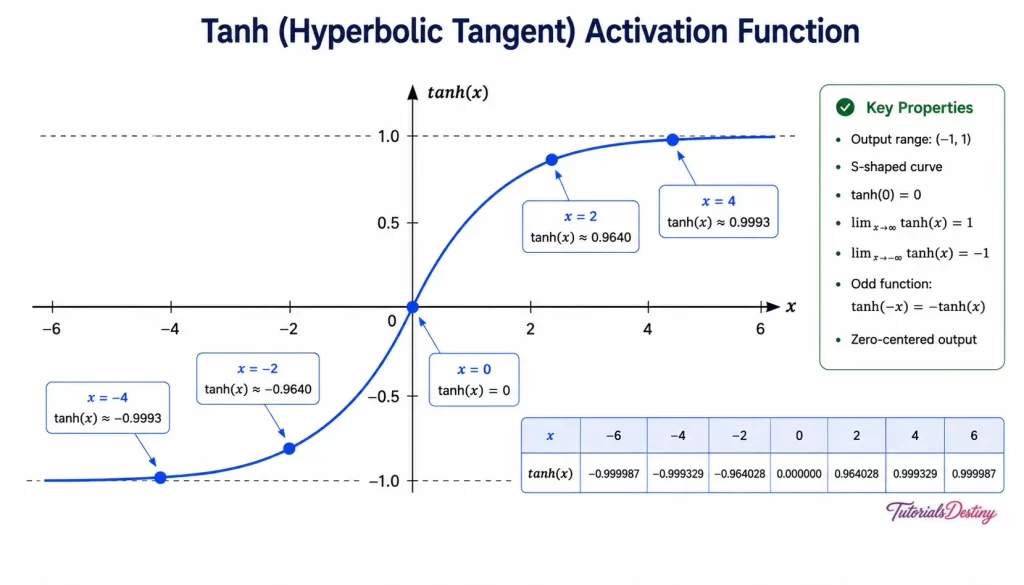
Interpretation
Tanh activation function maps any real-valued input to a value between -1 and +1. It is useful in hidden layer as it produces zero-centered outputs, which can help in faster convergence.
The shape resembles Sigmoid but is centered around zero.
Advantages of Tanh
Tanh offers:
- Stronger gradients
- Faster learning
- Better convergence
- Balanced positive and negative outputs
For many years, Tanh became a preferred activation function in numerous neural network architectures.
The ReLU Revolution
A major breakthrough occurred with the introduction of the Rectified Linear Unit (ReLU). Today, ReLU is one of the most widely used activation functions in Deep Learning.
Its simplicity and effectiveness transformed neural network training.
Understanding ReLU
The Rectified Linear Unit (ReLU) activation function is defined as:
This function is central to deep learning because it introduces non-linearity while remaining computationally efficient. It is the most commonly used activation function in the hidden layers of modern neural networks.
The ReLU function follows a simple rule, it outputs the input directly if it is positive otherwise it outputs zero
ReLU Visualization
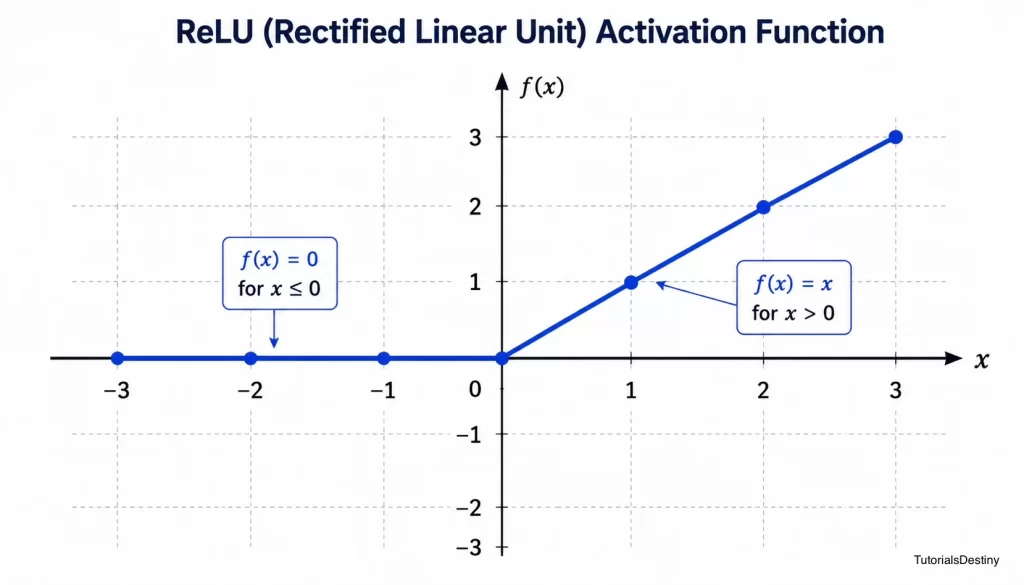
Negative values become zero. Positive values pass through unchanged.
Why ReLU Changed Deep Learning
ReLU offers several advantages:
Faster Training: Computations are simple and efficient.
Reduced Vanishing Gradients: Positive values maintain stronger gradients.
Improved Scalability: Deep networks containing hundreds of layers become easier to train. These advantages helped fuel the Deep Learning revolution.
Leaky ReLU: Fixing a ReLU Weakness
Although ReLU performs exceptionally well, it has one notable weakness. Some neurons may become permanently inactive. This issue is known as the “Dying ReLU” problem.
Leaky ReLU addresses this issue by allowing a small gradient for negative values.
As a result:
- Learning continues
- Neurons remain active
- Performance improves in some architectures
Comparing Activation Functions
| Function | Output Range | Strength |
| Step | 0 or 1 | Simple decisions |
| Sigmoid | 0 to 1 | Probability outputs |
| Tanh | -1 to 1 | Balanced outputs |
| ReLU | 0 to ∞ | Deep learning standard |
| Leaky ReLU | Small negative to ∞ | Improved ReLU variant |
Each activation function serves a different purpose. The choice depends on architecture and application requirements.
Building a Neural Network
A single neuron can perform only simple computations. To solve complex problems, we connect many neurons together.
These organized collections form neural networks. Neural networks are typically structured into layers.
Input Layer
│
Hidden Layer
│
Output Layer
Each layer plays a specific role in information processing.
Understanding the Input Layer
The Input Layer receives raw data.
Examples include:
Image Recognition
Input:
- Pixel values
House Price Prediction
Input:
- Area
- Bedrooms
- Location
Medical Diagnosis
Input:
- Age
- Symptoms
- Test results
The input layer simply receives information. No learning occurs here.
Understanding Hidden Layers
Hidden layers perform most of the network’s computation. They learn increasingly sophisticated representations of data.
For example, in image recognition:
First Hidden Layer
May detect:
- Edges
- Corners
- Lines
Second Hidden Layer
May detect:
- Shapes
- Textures
Third Hidden Layer
May detect:
- Eyes
- Wheels
- Faces
Each layer builds upon information learned by previous layers. This hierarchical learning process is one of Deep Learning’s greatest strengths.
Understanding the Output Layer
The Output Layer produces final predictions.
Examples:
Binary Classification
Spam
Not Spam
Multi-Class Classification
Cat
Dog
Bird
Horse
Regression
Predicted House Price
The structure of the output layer depends on the problem being solved.
What Makes Deep Learning “Deep”?
The term “Deep Learning” refers to neural networks containing multiple hidden layers.
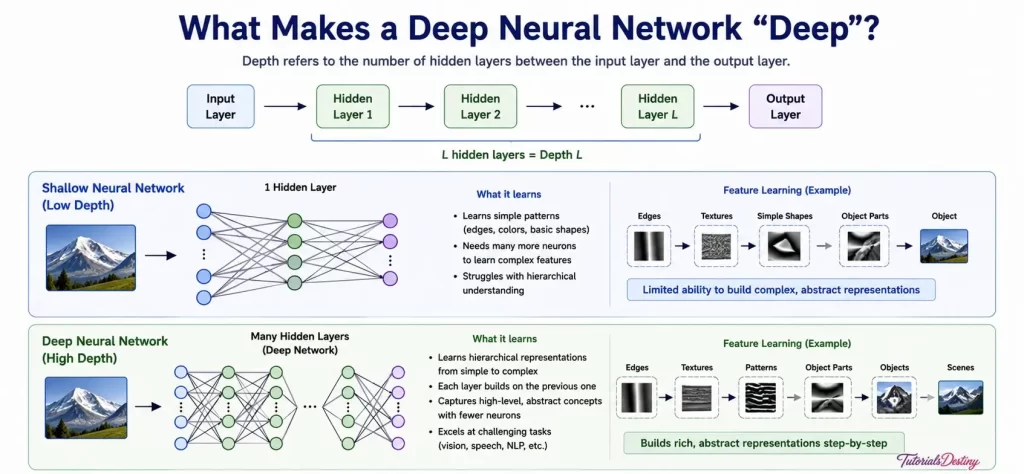
The greater the number of hidden layers, the deeper the network. Deep architectures enable learning of increasingly abstract representations.
Feature Learning vs Feature Engineering
Traditional Machine Learning relies heavily on feature engineering. Humans manually create useful features for models.
Deep Learning takes a different approach. The network learns features automatically. This capability represents one of the most significant advances in modern AI.
For example traditional image recognition may require manually defining:
- Edges
- Shapes
- Textures
Deep Learning automatically discovers these patterns during training.
Why Deep Learning Transformed AI
Deep Learning succeeded because it solved three major challenges simultaneously:
- Automatic Feature Learning: No extensive manual feature design required.
- Massive Data Processing: Can learn from enormous datasets.
- Scalable Architectures: Performance improves as models become larger.
These characteristics enabled breakthroughs across virtually every AI domain.
At this point, an important question remains: How does a neural network actually learn?
A neural network is not born with knowledge. When training begins, the network has no understanding of images, language, speech, or any other task.
Its weights are typically initialized with random values.
Yet after sufficient training, the same network can recognize objects, understand language, generate text, predict outcomes, and solve highly complex problems.
The secret lies in a learning process that continuously improves the network’s internal parameters based on experience.
This learning process forms the foundation of Deep Learning.
Understanding Forward Propagation
Whenever data enters a neural network, it moves through the network layer by layer until a prediction is produced.
This process is known as Forward Propagation.
During forward propagation:
- Input data enters the network.
- Each neuron performs calculations.
- Activation functions process outputs.
- Information flows through hidden layers.
- The output layer generates a prediction.
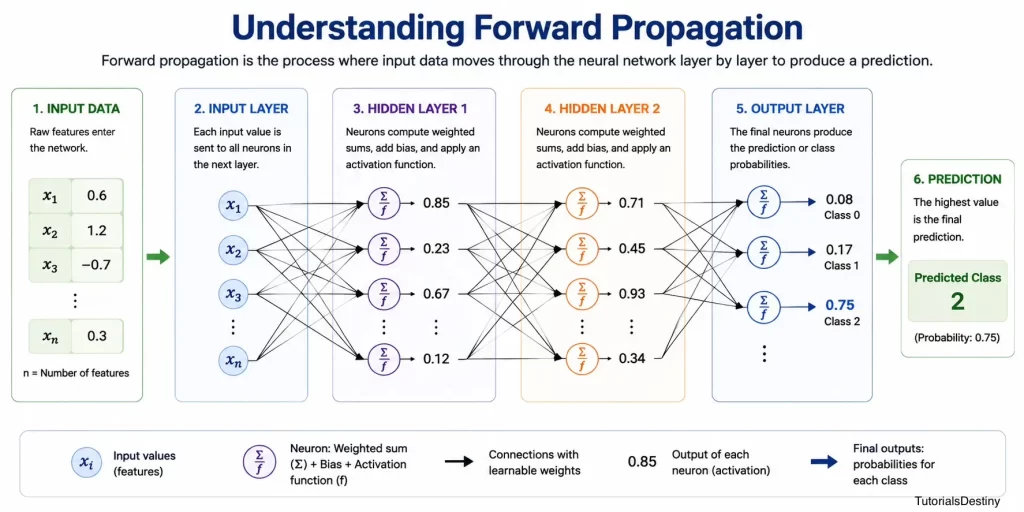
Every prediction made by a neural network begins with forward propagation.
A Real-World Example of Forward Propagation
Imagine a neural network designed to predict whether a student will pass an examination.
Input features:
- Attendance
- Study Hours
- Assignment Scores
Suppose a student has:
Attendance = 90%
Study Hours = 8
Assignments = 85%
These values enter the input layer.
Each neuron applies weights and activation functions. Information flows through hidden layers.
Eventually, the output layer may produce:
Pass Probability = 0.92
This means the network predicts a 92% chance of passing. The prediction is generated entirely through forward propagation.
The Role of Weights in Learning
Weights are the most important learnable components of a neural network.
Think of weights as importance scores.
For example:
When predicting house prices:
Location → Highly Important
Size → Important
Wall Color → Less Important
The network learns these importance values automatically.
At the start of training:
Weight 1 = Random
Weight 2 = Random
Weight 3 = Random
The network initially performs poorly. As training progresses, weights are adjusted repeatedly.
Eventually, the network discovers values that produce accurate predictions. Learning is essentially the process of finding optimal weights.
Understanding Bias
Along with weights, neural networks also learn a parameter called Bias. Bias provides additional flexibility.
Imagine a student evaluation system. Even if all inputs are zero, the system may still need to produce a meaningful output.
Bias helps shift activation thresholds and improves the network’s ability to fit complex patterns. Without bias, neural networks would be significantly less powerful.
Network Parameters
The learnable components of a neural network are collectively called Parameters.
Parameters include:
- Weights
- Biases
Modern deep learning models may contain:
- Thousands of parameters
- Millions of parameters
- Billions of parameters
Large Language Models such as ChatGPT contain enormous numbers of parameters that enable sophisticated language understanding and generation.
Why Learning Requires Error Measurement
Suppose a network predicts:
House Price = ₹50 lakh
Actual price:
House Price = ₹60 lakh
The prediction is incorrect.
How does the network know it made a mistake?
The answer lies in a mathematical mechanism called a Loss Function.
Loss functions measure prediction error.
The larger the error, the higher the loss.
The goal of training is simple:
Minimize loss as much as possible.
Understanding Loss Functions
A loss function quantifies how far predictions are from actual values.
Examples:
Small Error
Predicted = 98
Actual = 100
Loss is low.
Large Error
Predicted = 40
Actual = 100
Loss is high.
The network uses loss values to guide learning. Without loss functions, the network would have no way to improve itself.
The Learning Cycle of a Neural Network
Training follows a repeating cycle.
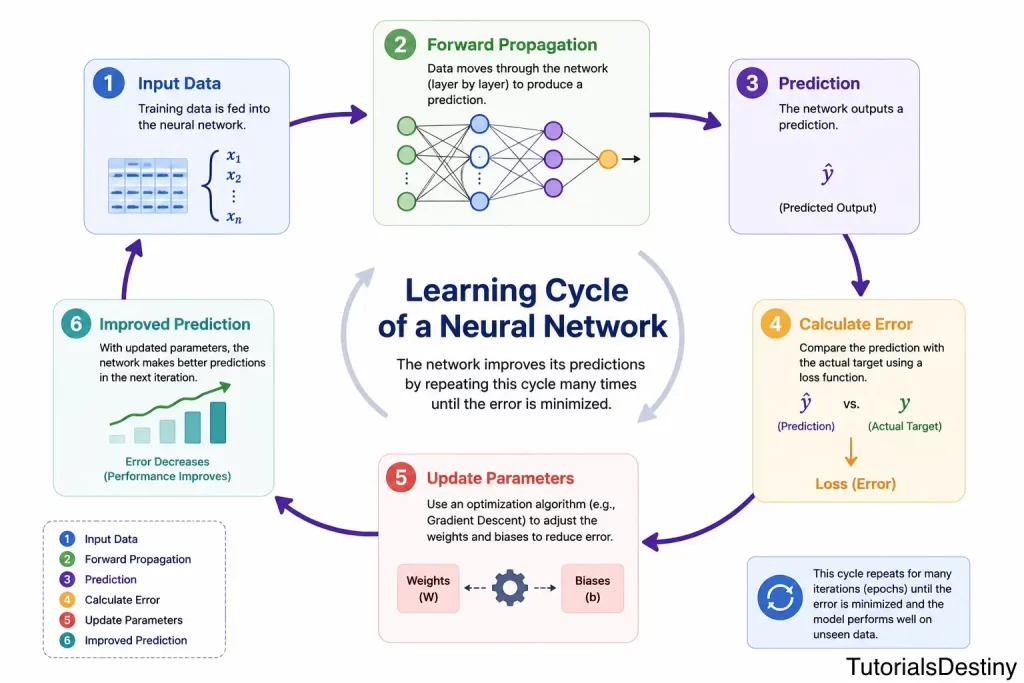
This cycle may repeat thousands of times or millions of times or billions of times depending on the complexity of the problem.
How Neural Networks Learn Patterns
One of the most remarkable abilities of neural networks is pattern recognition.
Consider image recognition.
Humans can instantly identify a dog. However, computers see only numerical pixel values. A neural network learns relationships among those pixels. Over time it discovers:
Early Layers
Learn simple features:
- Lines
- Edges
- Corners
Intermediate Layers
Learn more complex structures:
- Fur patterns
- Eyes
- Ears
Deep Layers
Learn complete concepts:
- Dogs
- Cats
- Cars
- Humans
This hierarchical learning process is a defining characteristic of Deep Learning.
Hierarchical Feature Learning
Traditional Machine Learning often depends on manually engineered features. Deep Learning automatically learns features at multiple levels.
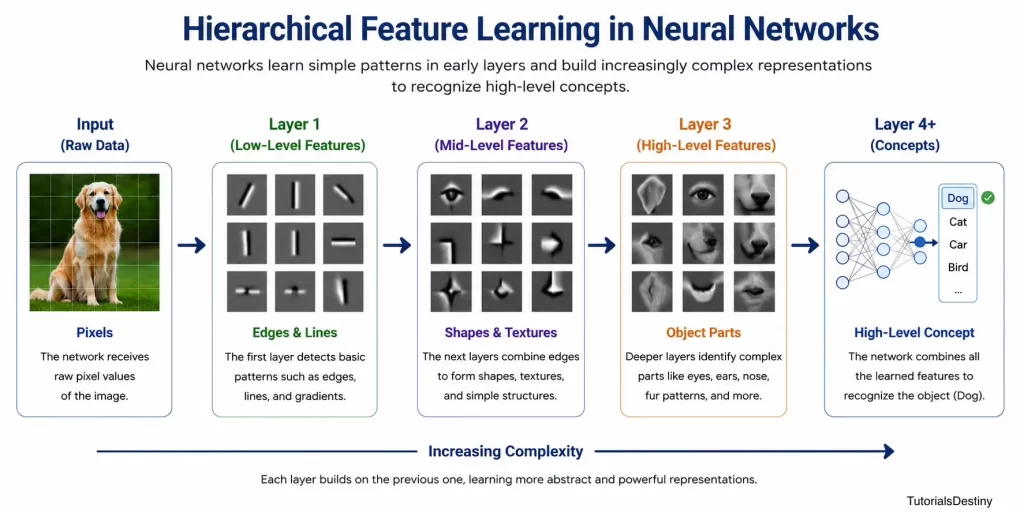
This ability dramatically reduces the need for manual feature engineering. It is one of the main reasons Deep Learning became so successful.
A Practical Image Recognition Example
Suppose we want to build a neural network that identifies cats. The network receives thousands of cat images.
Initially:
Accuracy ≈ Random Guessing
After training:
The network begins identifying:
- Fur textures
- Eye structures
- Ear shapes
- Facial patterns
Eventually, it learns the concept of a cat itself.
Importantly, developers never explicitly define these features. The network discovers them automatically.
Why Neural Networks Became Popular Again
Neural network concepts have existed for decades. However, early neural networks faced several limitations:
- Limited computing power
- Small datasets
- Training difficulties
As technology advanced, these obstacles began to disappear. Three developments fueled the Deep Learning revolution.
Big Data
Modern organizations generate enormous amounts of data.
Examples:
- Social media posts
- Images
- Videos
- Medical records
- Sensor data
Large datasets provide the information neural networks need to learn effectively.
Powerful Hardware
Training deep networks requires significant computation. The emergence of GPUs dramatically accelerated neural network training.
Tasks that once required weeks could now be completed in hours. This breakthrough enabled larger and deeper architectures.
Improved Algorithms
Researchers developed better techniques for:
- Optimization
- Initialization
- Activation functions
- Regularization
These innovations made deep networks easier to train and more effective.
Why Deep Learning Changed Artificial Intelligence
Deep Learning transformed AI because it solved problems that traditional approaches struggled with.
Examples include:
Image Recognition: Neural networks can identify objects with remarkable accuracy.
Applications:
- Medical imaging
- Security systems
- Autonomous vehicles
Speech Recognition: Voice assistants use neural networks to convert speech into text.
Examples:
- Siri
- Alexa
- Google Assistant
Natural Language Processing
Neural networks power:
- Translation systems
- Chatbots
- Language models
- Text summarization
Modern conversational AI relies heavily on deep learning architectures.
Recommendation Systems: Streaming platforms and online stores use neural networks to recommend content and products.
Examples:
- Netflix recommendations
- YouTube suggestions
- Amazon product recommendations
Autonomous Vehicles: Self-driving cars rely on neural networks to:
- Detect pedestrians
- Recognize traffic signs
- Track lane markings
- Make driving decisions
Without deep learning, autonomous driving would be far more difficult.
Strengths of Neural Networks
Neural networks offer several advantages.
- Automatic Feature Learning: Features are learned directly from data.
- High Predictive Power: Deep networks often outperform traditional methods on complex tasks.
- Scalability: Performance improves as more data becomes available.
- Flexibility: Neural networks can solve diverse problems across many domains.
Limitations of Neural Networks
Despite their strengths, neural networks are not perfect.
- Large Data Requirements: Deep networks often require substantial training data.
- Computational Cost: Training can be resource-intensive.
- Limited Interpretability: Many neural networks function as “black boxes.” Understanding their decisions can be challenging.
- Risk of Overfitting: Large networks may memorize training data if not properly managed.
Common Misconceptions About Neural Networks
Several misconceptions exist regarding neural networks.
Myth 1: Neural Networks Think Like Humans
They do not, they are inspired by biological neurons but operate very differently from the human brain.
Myth 2: Bigger Networks Are Always Better
Larger networks often perform better, but architecture quality and training data remain critical.
Myth 3: Neural Networks Eliminate the Need for Human Expertise
Human expertise remains essential for:
- Problem formulation
- Data preparation
- Evaluation
- Ethical considerations
Neural Networks in Modern AI Systems
Nearly every major AI breakthrough in recent years has involved neural networks.
Applications include:
- ChatGPT
- Large Language Models
- Image Generation Systems
- Speech Recognition Platforms
- Medical AI Systems
- Recommendation Engines
- Autonomous Vehicles
Understanding neural networks therefore provides the foundation for understanding modern Artificial Intelligence itself.
Interview Corner
Frequently Asked Interview Questions
What is an artificial neuron?
An artificial neuron is a computational unit that receives inputs, applies weights, processes information through an activation function, and produces an output.
Why are activation functions important?
Activation functions introduce non-linearity, allowing neural networks to learn complex patterns.
What is forward propagation?
Forward propagation is the process through which input data flows through a neural network to produce predictions.
What are weights and biases?
Weights determine input importance, while biases provide additional flexibility in decision-making.
Why is Deep Learning called “deep”?
Because the network contains multiple hidden layers that learn increasingly abstract representations.
What’s Next?
➡ Lesson 2: Deep Learning Architectures
In the next lesson, you will explore how multiple hidden layers enable neural networks to learn increasingly sophisticated representations, understand feedforward networks, representation learning, and discover why deeper architectures transformed Artificial Intelligence.
[Continue to Lesson 2 →]