A Conceptual and Practical Foundation in Python
Data structures are the architecture of analytical thinking in Python. Before visualization, before modeling, and even before statistical reasoning, there is a more fundamental question:
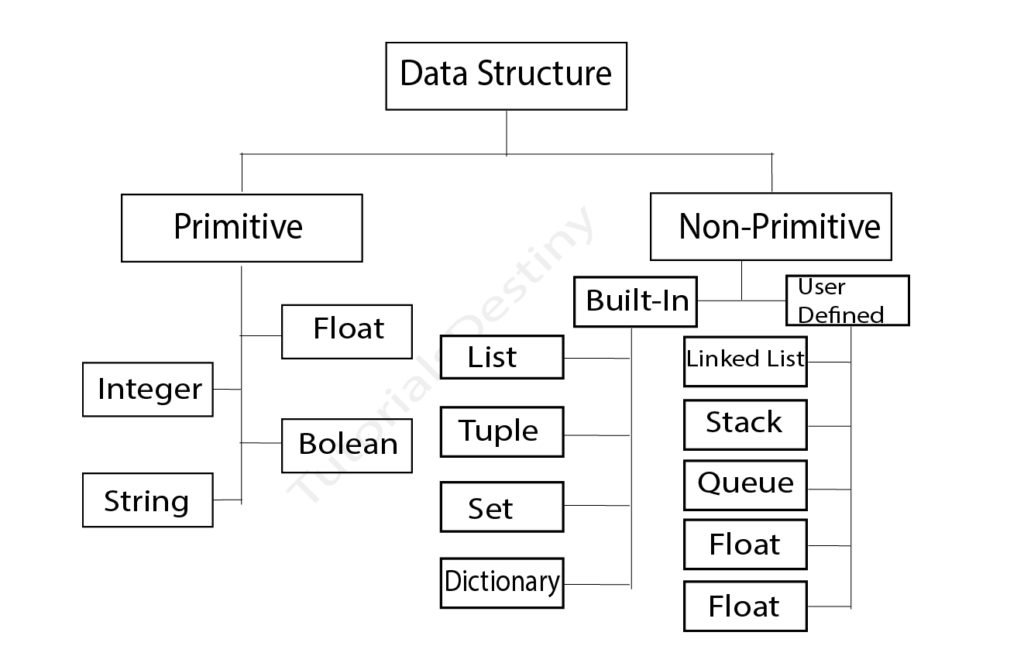
How is the data organized in memory? The answer to this question determines how efficiently you can manipulate information, how clearly you can express logic, and how scalable your workflow becomes.
In analytics, data structures are not abstract programming concepts. They directly influence how datasets are represented, transformed, and interpreted. When you clean a dataset, filter values, group categories, or compute aggregates, you are interacting with underlying structures that define how information is stored and retrieved.
This page develops a deep understanding of Python’s core data structures—lists, tuples, dictionaries, and sets—from an analytical perspective. The objective is not only to understand their mechanics, but to understand their strategic role in data work.
The Role of Data Structures in Analytical Workflows
Every dataset, regardless of size, must be represented internally in some structured format. Whether you are analyzing a small CSV file or working with large-scale machine learning pipelines, your analysis depends on how data is arranged.

Data structures influence:
- How easily you can access elements
- How efficiently you can modify values
- How clearly your logic maps to real-world meaning
- How well your code scales
Poor structural decisions lead to tangled logic and unnecessary complexity. Strong analytical programmers deliberately choose structures that align with the shape and purpose of their data.
Lists: Ordered Collections for Sequential Data
A list is an ordered, mutable collection of elements. It preserves sequence, which makes it naturally suited for representing time-based or position-based information.
In analytics, lists frequently appear when dealing with:
- Time series observations
- Sequential measurements
- Aggregated results from computations
- Iterative transformations
Because lists preserve order, they align well with real-world data that unfolds across time or follows a logical progression.
One of the most important characteristics of lists is mutability. You can add, remove, or modify elements dynamically. This flexibility is useful when collecting values during iteration or building intermediate results during preprocessing.
However, lists also have limitations. They do not enforce uniform data types, nor do they provide labeled access to elements. Access relies on positional indexing, which can reduce clarity when datasets grow complex.
From an analytical standpoint, lists are often an initial container—a staging structure before data is converted into more structured forms like arrays or DataFrames.
Tuples: Stability and Immutability
Tuples resemble lists in that they are ordered collections. The crucial difference is that tuples are immutable. Once created, their contents cannot be altered.
Immutability has conceptual importance in analytics. It signals that a collection represents a fixed logical unit. For example, a coordinate pair (latitude, longitude) or a configuration parameter set should not change during computation.
Using tuples communicates intent: this data should remain stable. That stability can prevent accidental modification and reinforce logical clarity.
Although tuples are less frequently used than lists in day-to-day analysis, they are essential in situations where data integrity is critical or when returning multiple values from functions.
In practical terms, tuples support structured thinking by distinguishing between flexible collections and fixed entities.
Dictionaries: Representing Structured Records
Dictionaries are arguably the most analytically expressive of Python’s built-in structures. They store data as key–value pairs, allowing direct access through meaningful labels rather than numeric positions.
This mirrors how structured data is conceptualized in real-world datasets. Consider a customer record:
- Name
- Age
- Location
- Purchase history
In dictionary form, each attribute becomes a key mapped to its corresponding value. This labeled access dramatically improves clarity compared to positional indexing.
Dictionaries are particularly powerful in analytics because they:
- Provide fast lookups
- Allow semantic labeling of data
- Support nested structures
- Align naturally with JSON and API responses
Many modern data pipelines involve ingesting JSON data, which maps directly into dictionaries or lists of dictionaries. Understanding dictionaries is therefore foundational for real-world data integration.
Nested dictionaries allow hierarchical representation, such as region → country → city → metrics. While powerful, nested structures require disciplined organization to avoid excessive complexity.
In many ways, dictionaries form the conceptual bridge between raw Python structures and higher-level tabular systems.
Sets: Managing Uniqueness and Comparison
A set is an unordered collection of unique elements. Unlike lists, sets automatically eliminate duplicates.
In analytics, uniqueness is often a central concern. You may need to identify distinct categories, remove duplicate identifiers, or compare overlapping groups.
Sets excel in these scenarios because they support mathematical set operations such as:
- Union (combining elements)
- Intersection (common elements)
- Difference (elements in one set but not another)
These operations become valuable when comparing customer segments, product categories, or experiment groups.
However, sets do not preserve order and do not allow indexed access. Their purpose is conceptual clarity around uniqueness and membership testing rather than sequential processing.
Structural Thinking in Analytical Practice
The choice of data structure is rarely random. It should reflect the analytical objective.
If your task involves ordered observations, a list may be appropriate. If you require labeled attributes, a dictionary provides clarity. If uniqueness is central, a set becomes ideal. If stability is necessary, a tuple reinforces immutability.
Strong analysts begin by asking: What is the logical structure of this data? Only then do they choose a container.
This structural awareness reduces code complexity and improves interpretability.
Iteration Across Structures
In analytics, iteration allows you to apply logic across collections of values. Whether computing totals, transforming categories, or filtering based on conditions, iteration connects structure to computation.
Lists and tuples are typically iterated sequentially. Dictionaries allow iteration over keys, values, or both. Sets can also be iterated, though without guaranteed order.
Understanding iteration patterns enables you to:
- Compute aggregates
- Transform raw inputs
- Apply classification rules
- Validate data integrity
Even when later transitioning to vectorized operations in pandas or NumPy, the mental model of iteration remains essential.
Combining Data Structures
Real analytical workflows rarely rely on a single structure. Instead, they involve combinations.
For example, a dataset might initially appear as a list of dictionaries, where each dictionary represents a record. Alternatively, you may encounter a dictionary of lists, representing column-oriented storage.
These combinations reflect different perspectives on the same dataset:
- Row-oriented representation
- Column-oriented representation
Recognizing these perspectives prepares you for understanding tabular data systems.
From Core Structures to Tabular Analytics
Higher-level libraries like pandas build upon these fundamental ideas. A DataFrame can be conceptualized as a structured system combining labeled columns, indexed rows, and efficient storage mechanisms.
When you understand Python data structures deeply, the transition to pandas feels natural rather than abrupt.
You begin to see that:
- Columns resemble structured sequences
- Rows resemble dictionaries
- Indexes provide labeled positioning
The abstraction becomes understandable because the foundation is clear.
Performance and Memory Awareness
While beginners focus primarily on clarity, understanding performance considerations becomes increasingly important as datasets scale.
Lists are dynamic and flexible but can become inefficient for heavy numerical computation. Dictionaries provide fast lookups but consume additional memory. Sets offer efficient uniqueness operations. Tuples are lightweight and stable.
As your analytical projects grow in size, these differences influence execution speed and resource usage.
Performance awareness does not mean premature optimization—it means understanding the structural trade-offs of each choice.
Common Structural Pitfalls
Analytical beginners often encounter recurring structural issues:
- Using lists when labeled access is needed
- Overcomplicating nested dictionaries
- Forgetting that sets are unordered
- Confusing positional indexing with semantic labeling
These mistakes typically arise from insufficient structural planning. Taking time to design data representation before analysis prevents such errors.
Data Structures as Cognitive Tools
Ultimately, data structures are not just storage mechanisms. They shape how you conceptualize problems.
When you use dictionaries, you think in terms of labeled attributes. When you use lists, you think in terms of sequences. When you use sets, you think in terms of membership and comparison.
This alignment between structure and cognition strengthens analytical reasoning.
Preparing for Advanced Applications
Mastering data structures prepares you for:
- Data cleaning and transformation
- Feature engineering
- Statistical computation
- Machine learning pipelines
- Scalable analytical systems
Every advanced analytical workflow rests on the disciplined use of foundational structures.
When learners struggle with pandas or machine learning libraries, the difficulty often stems not from the advanced tools themselves, but from a weak understanding of underlying structures.
Conclusion
Data structures are the structural grammar of analytical programming. They determine how information is organized, accessed, and transformed. Lists manage sequences. Tuples enforce stability. Dictionaries provide labeled structure. Sets ensure uniqueness.
Learning them is not a programming formality—it is the beginning of disciplined analytical thinking.
As you progress into more advanced topics, these structures will remain present—sometimes visible, sometimes abstracted. Mastering them now ensures clarity, efficiency, and confidence in every future analytical task.
Leave a Reply