Striking the Balance Between Learning and Generalization
Building a Machine Learning model is not simply about achieving high accuracy on a training dataset. The true goal of Machine Learning is to create models that can learn meaningful patterns from data and apply that knowledge effectively to new, unseen situations.
One of the biggest challenges in Machine Learning is finding the right balance between learning too little and learning too much. If a model is too simple, it may fail to capture important relationships in the data. If it becomes too complex, it may memorize the training data instead of learning general patterns.
These two problems are known as underfitting and overfitting, and understanding them is essential for building reliable Machine Learning systems.
Closely related to these concepts is the Bias-Variance Tradeoff, one of the most important principles in Machine Learning. It helps developers understand why models make errors and how to balance model complexity to achieve optimal performance.
Whether you are building a recommendation system, a fraud detection platform, a medical diagnosis tool, or a self-driving vehicle, understanding bias, variance, overfitting, and underfitting is crucial for creating AI systems that perform well in real-world environments.
In this lesson, we will explore these concepts in detail and learn practical strategies for developing models that generalize effectively.
By the end of this lesson, you will understand:
- What bias and variance mean
- The relationship between model complexity and performance
- What overfitting is and why it occurs
- What underfitting is and why it occurs
- The bias-variance tradeoff
- Techniques to reduce overfitting and underfitting
- Real-world implications of model performance
Why Model Performance Matters
Imagine a student preparing for an examination.
One student memorizes every answer from previous years without understanding the concepts. Another student studies only a few topics and ignores much of the syllabus.
Both approaches can lead to problems.
The student who memorizes everything may struggle when questions change slightly.
The student who studies too little may fail to answer many questions.
Machine Learning models behave similarly.
A model that memorizes training data suffers from overfitting.
A model that learns too little suffers from underfitting.
The goal is to develop a model that understands the underlying patterns rather than simply memorizing examples.
Understanding Model Complexity
Model complexity refers to how flexible a Machine Learning model is when learning patterns from data.
Simple models:
- Learn basic relationships
- Require fewer parameters
- Are easier to interpret
Complex models:
- Learn intricate patterns
- Use many parameters
- Can represent sophisticated relationships
Neither simplicity nor complexity is automatically better.
The challenge is selecting a model that is complex enough to learn useful patterns but simple enough to generalize to new data.
The Model Complexity Spectrum
One of the most important decisions in Machine Learning is determining how complex a model should be. A model that is too simple may fail to capture important relationships in the data, while a model that is too complex may learn unnecessary details and become unreliable when exposed to new information.
This relationship between model complexity and performance can be visualized as a spectrum. At one end, we have models that are too simple and suffer from underfitting. At the other end, we have models that are overly complex and suffer from overfitting. Between these two extremes lies the ideal balance where a model learns meaningful patterns and generalizes effectively.
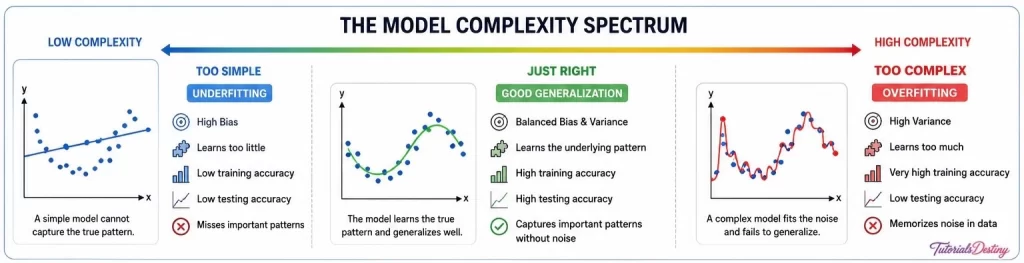
Understanding this spectrum helps developers recognize why increasing model complexity does not always lead to better results. In fact, adding more layers, parameters, or features can sometimes make a model less effective when applied to real-world situations.
The Left Side: Models That Are Too Simple
When a model is overly simple, it lacks the flexibility needed to capture meaningful relationships within the dataset. Such models make strong assumptions about the data and often ignore important patterns.
For example, imagine trying to represent a complex curved relationship using only a straight line. No matter how much data is provided, the model will struggle because it lacks the capability to learn the underlying structure.
Characteristics of overly simple models include:
- High bias
- Poor learning capability
- Low training accuracy
- Low testing accuracy
- Failure to capture important patterns
These models suffer from underfitting because they do not learn enough from the training data.
The Middle: The Sweet Spot
The center of the spectrum represents the ideal balance between simplicity and complexity.
At this point, the model is powerful enough to learn meaningful relationships while still maintaining the ability to generalize to unseen data. It captures genuine patterns rather than memorizing individual examples.
A well-balanced model typically demonstrates:
- Strong training performance
- Strong testing performance
- Good generalization
- Stable predictions
- Reduced prediction errors
This region is where Machine Learning practitioners aim to position their models.
The goal is not to create the most complex model possible but rather the model that achieves the best balance between learning and generalization.
The Right Side: Models That Are Too Complex
As model complexity increases, the model becomes increasingly capable of fitting every detail in the training dataset.
Initially, this may improve performance. However, beyond a certain point, the model begins learning noise, random fluctuations, and insignificant details.
Instead of understanding general patterns, it starts memorizing specific examples.
Characteristics of overly complex models include:
- High variance
- Excellent training accuracy
- Poor testing accuracy
- Sensitivity to small data changes
- Weak real-world performance
These models suffer from overfitting because they learn too much from the training data.
Why More Complexity Is Not Always Better
Many beginners assume that larger models automatically produce better results. While complex models can capture sophisticated patterns, they also require careful management.
Consider a student preparing for an examination. A student who understands the concepts can answer both familiar and unfamiliar questions. A student who memorizes every practice question may perform well on familiar problems but struggle when the questions change.
Overfitted Machine Learning models behave similarly. They excel on training data but fail when confronted with new situations.
This is why successful Machine Learning development focuses on finding the optimal level of complexity rather than maximizing it.
Finding the Optimal Position on the Spectrum
Machine Learning engineers use several techniques to keep models near the optimal point on the complexity spectrum:
- Cross-validation
- Regularization
- Feature selection
- Early stopping
- Dropout
- Hyperparameter tuning
- Data augmentation
These techniques help prevent models from becoming excessively simple or excessively complex.
By carefully balancing bias and variance, developers can create models that learn effectively while maintaining strong real-world performance.
What is Bias in Machine Learning?
Bias refers to errors caused by overly simplistic assumptions in a model.
A high-bias model pays insufficient attention to the training data and fails to capture important relationships.
As a result, it makes systematic mistakes.
In simple terms Bias occurs when a model learns too little from the data. High-bias models often produce poor predictions because they oversimplify the problem.
Real-World Example of Bias
Suppose a real estate company wants to predict house prices.
The actual price depends on:
- House size
- Location
- Number of bedrooms
- Property age
- Nearby facilities
If the model only considers house size and ignores all other factors, its predictions may be inaccurate.
The model has introduced bias because it failed to capture important relationships.
Characteristics of High-Bias Models
High-bias models often:
- Oversimplify problems
- Miss important patterns
- Perform poorly on training data
- Perform poorly on testing data
- Lead to underfitting
Because they learn too little, they cannot represent the true complexity of the problem.
What is Variance in Machine Learning?
Variance refers to how sensitive a model is to changes in training data.
A high-variance model learns training data extremely well, including noise and random fluctuations.
Instead of learning general patterns, it memorizes specific examples.
As a result Variance occurs when a model learns too much from the data.
Such models may perform exceptionally well on training data but poorly on new data.
Real-World Example of Variance
Imagine a teacher creates a practice test containing 100 questions.
A student memorizes every answer without understanding the concepts.
When the actual examination contains different questions, the student struggles.
The student memorized examples rather than learning the underlying principles.
This is similar to what happens in high-variance Machine Learning models.
Characteristics of High-Variance Models
High-variance models typically:
- Learn excessive detail
- Memorize training data
- Perform extremely well on training data
- Perform poorly on testing data
- Lead to overfitting
Such models fail to generalize effectively.
Understanding Underfitting
Underfitting occurs when a model is too simple to learn important patterns from data.
The model cannot capture the underlying structure of the problem.
As a result, it performs poorly on both training and testing datasets.
Signs of Underfitting
Common indicators include:
- Low training accuracy
- Low testing accuracy
- Poor predictions
- Inability to capture relationships
- High bias
The model is essentially “under-learning.”
Example of Underfitting
Suppose a dataset contains a curved relationship between variables.
If we use a straight-line model to represent this data, the model may fail to capture the curve.
The result is poor performance.
The model is too simple for the problem.
Why Underfitting Happens
Underfitting can occur due to:
- Oversimplified models
- Insufficient training time
- Poor feature selection
- Limited training data
- Excessive regularization
When important information is ignored, learning becomes ineffective.
Consequences of Underfitting
Underfitting leads to:
- Inaccurate predictions
- Missed patterns
- Poor decision-making
- Reduced model usefulness
Organizations relying on underfit models may lose valuable insights hidden within their data.
Understanding Overfitting
Overfitting occurs when a model learns the training data too closely.
Instead of identifying general patterns, it memorizes details, noise, and random fluctuations.
This results in excellent training performance but poor real-world performance.
Signs of Overfitting
Common indicators include:
- Extremely high training accuracy
- Low testing accuracy
- Large gap between training and testing performance
- Poor generalization
The model appears successful during development but struggles after deployment.
Example of Overfitting
Suppose a student memorizes every practice question before an exam.
When the actual exam contains slightly different questions, the student performs poorly.
The student memorized examples instead of learning concepts.
Overfitted Machine Learning models behave similarly.
Why Overfitting Happens
Several factors can cause overfitting:
- Excessive model complexity
- Too many features
- Small training datasets
- Noisy data
- Insufficient validation
- Excessive training iterations
When models become too flexible, they may start learning random noise instead of meaningful patterns.
Consequences of Overfitting
Overfitting can lead to:
- Poor real-world predictions
- Unreliable AI systems
- Reduced trustworthiness
- Increased maintenance costs
In critical applications such as healthcare or finance, overfitting can have serious consequences.
Comparing Underfitting and Overfitting
| Characteristic | Underfitting | Overfitting |
| Model Complexity | Too Simple | Too Complex |
| Training Accuracy | Low | Very High |
| Testing Accuracy | Low | Low |
| Generalization | Poor | Poor |
| Bias | High | Low |
| Variance | Low | High |
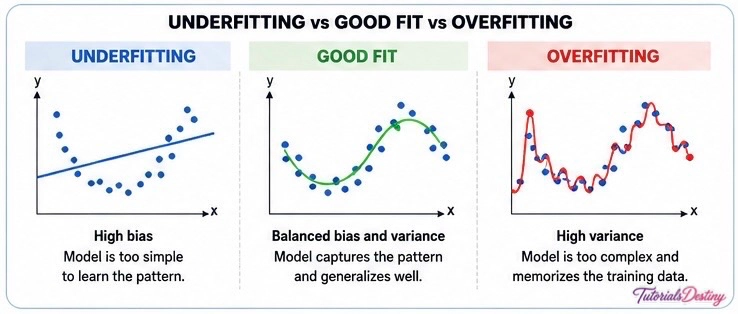
The goal is to avoid both extremes.
The Ideal Model
An effective Machine Learning model should:
- Learn meaningful patterns
- Ignore random noise
- Perform well on training data
- Perform well on testing data
- Generalize effectively
This balance is achieved through proper model design and evaluation.
What is the Bias-Variance Tradeoff?
The Bias-Variance Tradeoff describes the balance between two competing sources of error:
- Bias
- Variance
Reducing one often increases the other.
For example:
- Making a model more complex may reduce bias but increase variance.
- Simplifying a model may reduce variance but increase bias.
Developers must find the optimal balance.
Visualizing the Bias-Variance Tradeoff
Think of an archer aiming at a target.
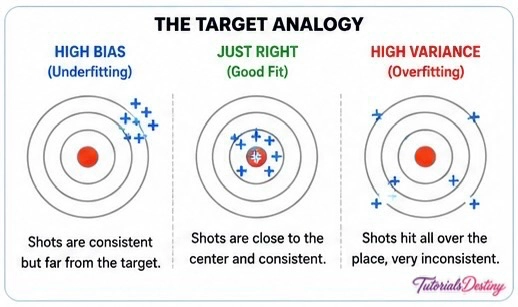
High Bias
Shots consistently miss the target in the same direction.
The archer has a systematic error.
This represents underfitting.
High Variance
Shots land randomly across the target.
Results are inconsistent.
This represents overfitting.
Balanced Model
Shots cluster closely around the center.
This represents good generalization.
Why the Tradeoff Matters
Every Machine Learning model contains some amount of bias and variance.
The objective is not to eliminate them completely.
Instead, developers aim to minimize total prediction error by balancing both factors.
Understanding this tradeoff helps create models that perform reliably on unseen data.
Techniques to Reduce Underfitting
Several strategies can help reduce underfitting.
Increase Model Complexity
More sophisticated models can learn richer patterns.
Examples include:
- Decision Trees
- Random Forests
- Neural Networks
Add Relevant Features
More informative features can improve learning.
Train Longer
Additional training iterations may improve performance.
Reduce Regularization
Excessive restrictions can prevent learning.
Removing unnecessary constraints may help.
Techniques to Reduce Overfitting
Several methods help reduce overfitting.
Collect More Data
Larger datasets expose models to greater variety.
This improves generalization.
Feature Selection
Removing irrelevant features reduces complexity.
Cross-Validation
Cross-validation helps evaluate models more reliably.
Regularization
Regularization discourages excessive complexity.
Early Stopping
Training stops before the model begins memorizing noise.
Dropout (Deep Learning)
Random neurons are temporarily disabled during training.
This prevents over-reliance on specific patterns.
Regularization Explained
Regularization is one of the most effective methods for controlling overfitting.
It introduces penalties for excessive model complexity.
The goal is to encourage simpler and more generalizable solutions.
Popular techniques include:
- L1 Regularization
- L2 Regularization
- Elastic Net
These methods are widely used in modern Machine Learning systems.
Cross-Validation and Generalization
Cross-validation evaluates a model using multiple training and testing splits.
Benefits include:
- Better performance estimates
- Reduced evaluation bias
- Improved model selection
- Better detection of overfitting
Professional Machine Learning workflows often rely heavily on cross-validation.
Real-World Example: Medical Diagnosis
Consider a Machine Learning model used to detect diseases.
Underfitting Scenario
The model ignores many important medical indicators.
Result:
- Poor diagnosis accuracy
- Missed diseases
Overfitting Scenario
The model memorizes patient records from one hospital.
Result:
- Performs poorly in other hospitals
Balanced Model
The model learns general medical patterns.
Result:
- Reliable diagnosis across different populations
This demonstrates why balancing bias and variance is critical.
Bias-Variance Tradeoff in Deep Learning
Deep Learning models contain millions or even billions of parameters.
Because of their complexity, they are highly susceptible to overfitting.

Modern techniques such as:
- Dropout
- Batch normalization
- Data augmentation
- Early stopping
help control variance while maintaining learning capability.
These techniques are fundamental in modern AI development.
Key Takeaways
- Bias occurs when a model learns too little.
- Variance occurs when a model learns too much.
- Underfitting results from high bias.
- Overfitting results from high variance.
- Both underfitting and overfitting reduce model effectiveness.
- The Bias-Variance Tradeoff helps balance model complexity.
- Good models generalize well to unseen data.
- Regularization and cross-validation help improve performance.
- Model evaluation is essential for detecting performance issues.
Conclusion
The Bias-Variance Tradeoff is one of the most fundamental concepts in Machine Learning. Every model must balance learning enough information to capture meaningful patterns while avoiding excessive complexity that leads to memorization.
Underfitting occurs when a model learns too little, while overfitting occurs when it learns too much. Both problems reduce a model’s ability to make accurate predictions in real-world environments.
By understanding bias, variance, model complexity, regularization, and validation techniques, developers can create Machine Learning systems that generalize effectively and deliver reliable performance.
In the next lesson, we will explore Evaluation and Performance Metrics, where we will learn how to measure model performance using accuracy, precision, recall, F1-score, confusion matrices, and other essential evaluation tools used throughout the AI industry.